With the new Version 3.2 we have introduced a new feature called “Satellite Collections”. This post explains what this is all about, how it can help you, and explains a concrete use case for which it is essential.
Background and Overview
Join operations are very useful but can be troublesome in a distributed database. This is because quite often, a join operation has to bring together different pieces of your data that reside on different machines. This leads to cluster internal communication and can easily ruin query performance. As in many contexts nowadays, data locality is very important to avoid such headaches. There is no silver bullet, because there will be many cases in which one cannot do much to improve data locality.
One particular case in which one can achieve something, is if you need a join operation between a very large collection (sharded across your cluster) and a small one, because then one can afford to replicate the small collection to every server, and all join operations can be executed without network communications.
This is what the Satellite Collections do. In ArangoDB, a Satellite Collection is one that has exactly one shard which is automatically replicated synchronously to every DBserver in the cluster. Furthermore, the AQL query optimizer can recognize join operations with other sharded collections and organize the query execution such that it takes advantage of the replicated data and avoid a lot of costly network traffic.
The name “Satellite Collection” comes from the mental image of a smallish collection (the satellite) which orbits around all the shards of a larger collection (the bigger planets), always close at hand for a next join operation, replacing interplanetary traffic with a quick surface orbit shuttle.
A concrete use case
Imagine that you have an IoT use case with lots of sensor data from a variety of devices. The set of individual events is clearly too large for a single server, but the number of devices is small enough to replicate to each server. If you now need to select certain events, usually restricted by their timestamp, but also filtered according to some condition on the device which produced the event, you have to bring together the data of an event with the data of its device.
One approach is to embed the device data with every event, thereby avoiding any join operation. This needs a lot more storage in the first place, but it also has other disadvantages. First of all, it contradicts the principle of data normalization, because device data is stored redundantly. Secondly (and of course related), there is no longer a single place holding all device data, so it is hard to get an overview over all devices or something like this.
The other sensible approach is to keep the device data separately, say in a smaller collection, and join an event to its device via a foreign key. This is the usual relational approach, which makes a lot of sense.
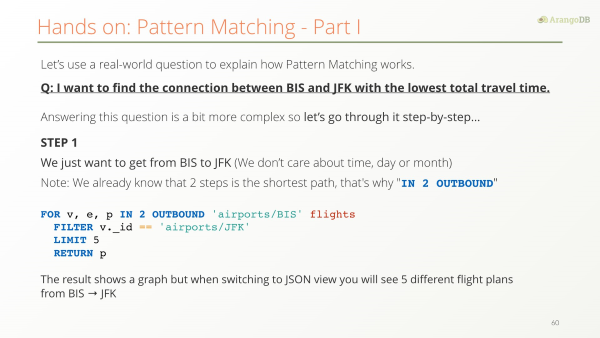
However, it requires a join operation for a query like this:
FOR e IN events
FILTER e.timestamp >= "123123123223" && e.timestamp <= "125212323232"
FOR d IN devices
FILTER e.device == d._key
FILTER d.firmwareVersion == "17"
return eObviously, we assume that the large events collection has a sorted index on the timestamp attribute.
This fetches all events in a prescribed time range whose corresponding device has firmware version 17, which is a query that could very well occur in practice. There are lots of similar use cases, the crucial ingredient is that a join between a large and a small collection is needed.
Performance gain
Let’s see what the query engine has to do to execute the above query.
It almost certainly wants to use the index on timestamp, so, on each shard of the events collection it uses this index to find the corresponding events. For each such event found it now has to find the corresponding device to do the filtering on the firmwareVersion attribute.
In the non-satellite case the query engine has to take all found events, move them to the place where the small devices collection is held, then perform a lookup for each such event, and then either discard the event or put it into the result set, if the firmware version matches.
ArangoDB will even collect all results from all shards on the coordinator and then send them on to the DBserver that holds the devices. The result set will be sent back to the coordinator and then to the client.
Let’s analyze this with a few concrete numbers. Assume that there is billion events and a million of them lie in the time range in which we are interested. Assume furthermore, that about one in 1000 devices has the particular firmware and that the events are evenly distributed between the devices.
Then the above query will find a million out of a billion, distributed across the shards of the events collection. Altogether, it will send a million events across the network to the coordinator (each from one of the shards), and then send all of them to the DBserver holding the devices. There it will perform a million lookups locally and discard 999 out of 1000 devices, producing 1000 results, which are sent back to the coordinator. Altogether, we have sent a million events two times over the wire, this is expensive.
If the devices collection is a Satellite Collection, then the data is resident on each server, that is, close to each shard of the events collection. Therefore, the query optimizer can select the events in the time range in question on each shard, and directly perform the lookup for the device, without any network traffic. It discards most of them because of the firmware version and only has to send the 1000 results back to the coordinator and then to the client. It could even perform this in a completely parallel fashion, but this is a future performance enhancement.
That is, the net savings effect, in this case, is not to have to send a million events across the wire twice. If you assume that an event uses 500 bytes, then this is network transfer of approximately 1GB. On a fast ethernet this takes approximately 100s. On gigabit ethernet it is only 8s under optimal conditions, but this is still noticeable.
Our experiments actually confirm these savings in network traffic and time. In the coming weeks we will publish a benchmark including all the data used and measurements done, so watch out for more details.
How to try it out
This is fairly easy. First of all, you have to know that the Satellite Collections are a feature of the enterprise version. So once you have a cluster running that (we offer a free trial license), you simply create your collections as usual, create the smaller one with "numberOfShards":1 and "replicationFactor":"satellite". From then on, your join operations should be faster, provided the query optimizer discovers the situation and acts accordingly. Use the explain feature in the UI or in JavaScript to check the execution plan used. If in doubt, we are always happy to help diagnosing what is going on.
Obviously, a collection that is replicated synchronously to all DBservers has a larger latency on writes. However, we would assume that such a Satellite Collection has a smaller write bandwidth than the larger events collection.
Let me close with another word of warning: Satellite Collections are a nice and very useful feature, but they need planning to unfold their full potential. Please contact us, if you have a particular use-case in mind.


 Mike has over 20 years of experience at public, private, as well as venture-backed startups with a particular focus on open source technologies. He’s an accomplished software sales executive with strong leadership, team building, and business development skills. Most recently, Mike was responsible for growing the Western Territory at MariaDB and Basho Technologies. He helped several companies over two decades leading to acquisitions from Morgan Stanley, Yahoo, and VMware.
Mike has over 20 years of experience at public, private, as well as venture-backed startups with a particular focus on open source technologies. He’s an accomplished software sales executive with strong leadership, team building, and business development skills. Most recently, Mike was responsible for growing the Western Territory at MariaDB and Basho Technologies. He helped several companies over two decades leading to acquisitions from Morgan Stanley, Yahoo, and VMware.



 Claudius Weinberger, Co-Founder and CEO, declared: “We’ve found in Target Partners a supportive and knowledgeable investor. After reaching important business milestones and expanding our customer footprint globally, we will use this funding to further accelerate and strengthen our US-based presence.”
Claudius Weinberger, Co-Founder and CEO, declared: “We’ve found in Target Partners a supportive and knowledgeable investor. After reaching important business milestones and expanding our customer footprint globally, we will use this funding to further accelerate and strengthen our US-based presence.”  Kurt Müller, Partner at Target Partners said: “Our investment in ArangoDB has proved to be very successful. After gaining traction on the product side, the company aggressively moved to sign landmark deals with some of the largest global organizations. This motivated us to further invest in the team and the growth.”
Kurt Müller, Partner at Target Partners said: “Our investment in ArangoDB has proved to be very successful. After gaining traction on the product side, the company aggressively moved to sign landmark deals with some of the largest global organizations. This motivated us to further invest in the team and the growth.”




 As data gets bigger, faster and more complex, you need to arm yourself with the best tools. In this webinar we’ll see how KeyLines and ArangoDB combine to create powerful and intuitive data analysis platforms.
As data gets bigger, faster and more complex, you need to arm yourself with the best tools. In this webinar we’ll see how KeyLines and ArangoDB combine to create powerful and intuitive data analysis platforms. Next Christian Miles, Technical Sales Manager at Cambridge Intelligence, will show how graph visualization makes that back-end power accessible to users. He’ll use a complex IT network visualization to demonstrate how a KeyLines component can help your users cut through complexity and overcome data scale to reveal insights.
Next Christian Miles, Technical Sales Manager at Cambridge Intelligence, will show how graph visualization makes that back-end power accessible to users. He’ll use a complex IT network visualization to demonstrate how a KeyLines component can help your users cut through complexity and overcome data scale to reveal insights.


 ) and ensure the shard is properly placed. Then you can make your guess.
) and ensure the shard is properly placed. Then you can make your guess.








