nihil novi nisi commune consensu
nothing new unless by the common consensus
– law of the polish-lithuanian common-wealth, 1505
A warning aforehand: this is a rather longish post, but hang in there it might be saving you a lot of time one day.
Introduction
Consensus has its etymological roots in the latin verb consentire, which comes as no surprise to mean to consent, to agree. As old as the verb equally old is the concept in the brief history of computer science. It designates a crucial necessity of distributed appliances. More fundamentally, consensus wants to provide a fault-tolerant distributed animal brain to higher level appliances such as deployed cluster file systems, currency exchange systems, or specifically in our case distributed databases, etc.
While conceptually, one could easily envision a bunch of computers on a network, who share and manipulate some central truth-base, the actual implementation of such a service will pose paradoxical demands to fail-safety and synchronicity. In other words, making guarantees about the truth of state x at a given time t or more demanding at any given time {t1,…,tn} turns out to be entirely and radically non-trivial.
This is the reason, why most implementations of consensus protocols as deployed in real production systems have relied upon one of two major publications1,2 referred to by their synonyms, Paxos, including its derivatives, and RAFT, respectively.
![consensus]()
Although it would be a beastly joy to discuss here the differences and the pro and contra argumentation of each, I suggest to have a look at the extent of both papers in excess of 15 pages to get a rough idea of the scope of such a discussion. As a matter of fact we were as audacious to try to define and implement a simpler protocol than the above. And we failed miserably – at least in arriving at a simpler solution.
Suffice it to say that we decided to utilise RAFT in our implementation. The choice for RAFT fell mainly because in my humble view it is the overall simpler method to understand.
In short, RAFT ensures at all times that one and only one instance of the deployed services assumes leadership. The leader projects permanently its reign over other instances, replicates all write requests to its followers and serves read requests from its local replica. As a matter of fact, it is crucial to note that the entire deployment needs to maintain the order of write requests, as arbitrary operations on the replicated log will not be commutable.
Furthermore and not least importantly, RAFT guarantees that any majority of instances is functional i.e. is capable of electing a leader and knows the replicated truth as promised to the outside world.
For more on RAFT and consensus in general, we would like to refer to the authors’ website.
What is already out there and why not just take one of those
Say that you have realised by now that you need such a consensus among some set of deployed appliances. Should you do the implementation yourself? Most probably not. Unless obviously, you have good reasons. As there are multiple arguably very good implementations of both of the above algorithms out there. They come as code snippets, libraries or full-fledged services; some of which have enjoyed praise and criticism alike.
Common wisdom suggests to invest your development energy in more urgent matters that will put you ahead of your competition, or at least to spare the tedious work of proving the correctness of the implementation all the way to deliberate abuse case studies.
We, initially, started off building ArangoDB clusters before version 3.0 relying on etcd. etcd is a great and easy to use service, which is actively maintained and developed to date. We did hit limits though as we did have need for replication of transactions rather than single write requests, which etcd did not provide back then. We also dismissed other very good services such as zookeeper, as zookeeper, for example, would have added the requirement to deploy a Java virtual machine along. And so on.
But the need for our own consensus implementation imposed itself upon us for other reasons.
I mentioned earlier the consensus to be the animal brain of a larger service. When we think of our brainstem the first thing that comes to mind is not its great capabilities in storing things but its core function to control respiration and heart beat. So how about being able to make guarantees not only about replicating a log or key-value-store but also running a particular process as a combined effort of all agents. In other words, could one think of a resilient program thread which follows the RAFT leadership? And if so, what would the benefits look like?
Letting the cat entirely out of the bag, we built into the RAFT environment a supervision process, which handles failure as well as maintenance cases at cluster runtime. None of the implementations we were aware of could provide us with that. In my view the most intriguing argument.
This is how we use the agency
After all the nice story telling, let us look how we ended up using the agency.
![cluster topology]()
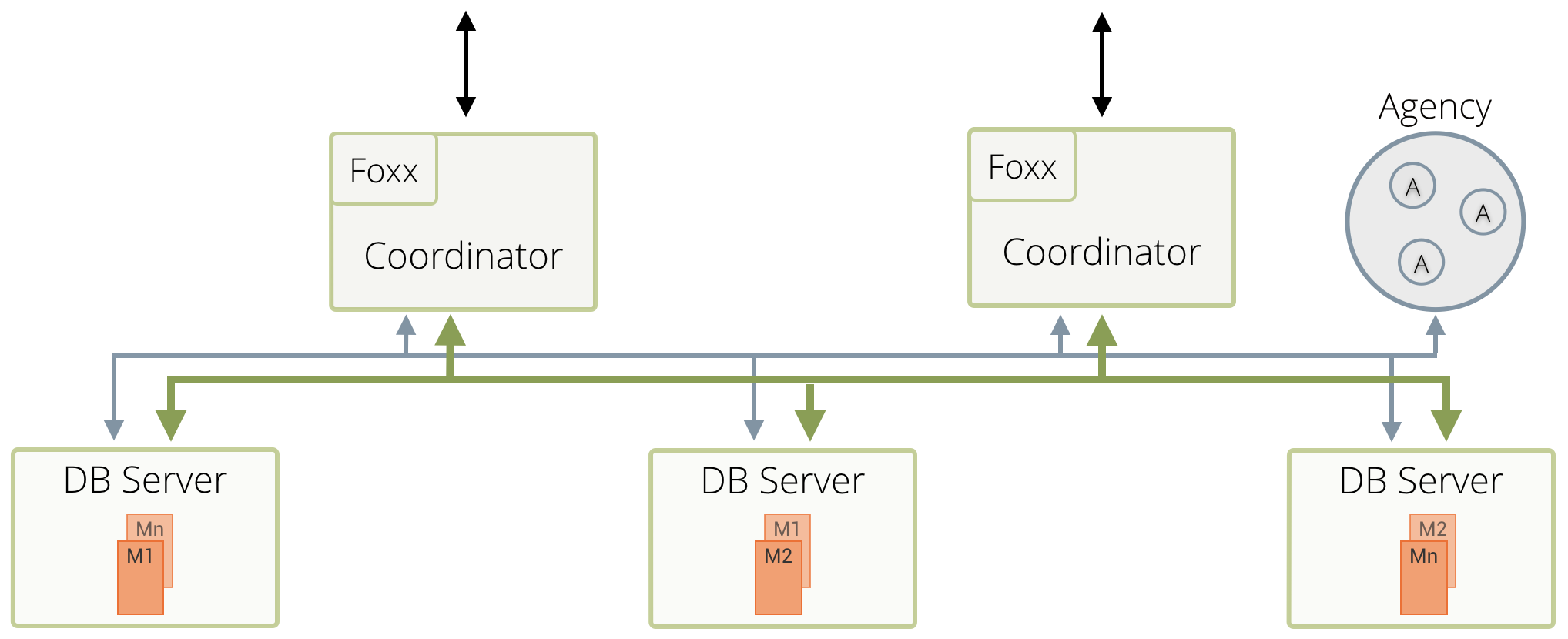
ArangoDB cluster deployments consist of 3 types or roles of services, namely database servers, coordinators and agents. For details on the function of the first two roles, please refer to the cluster documentation. For them however to function and interact properly they rely on our distributed initialisation and configuration.
Every imaginable meta information is stored there. Which instance is storing a replica of a particular shard? Which one is the primary database server currently responsible for shard X or synchronous replication of shard Y as a follower and vice versa. When was the last heartbeat received from which service. etc.
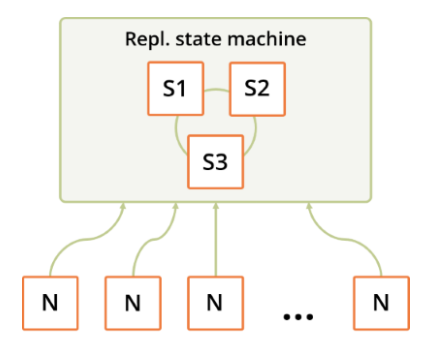
ArangoDB-speak for the central cluster maintenance and configuration consensus is agency. The agency consists of an odd number of ArangoDB instances, which hold the replicated and persisted configuration of the cluster while maintaining integrity using the RAFT algorithm in their midst.
Database servers and coordinators interact with the agents through an HTTP API. Agents respond as a unit. Read and write API calls are redirected seamlessly by followers to the current leader. Changes in cluster configuration are stored in the “Plan” section of the key value store while actually committed changes are reported by the database servers and coordinators in the “Current” section. A single API call to the agency may consist of a bundle of transactions on the key value store, which are executed atomically with guarantees to transaction safety.
Last but not least, the agency holds a supervision thread whose job it is to perform automated failover of db servers with all the consequences for individual shards of individual collections. But it is also the place where deliberate maintenance jobs are executed such as orderly shutdown of a node for say hardware upgrade and the like.
Having all the power of consensus in such a program, we can guarantee that no 2 machines start giving contradictory orders to the rest of the cluster nodes. Additionally, a job like handling a failed server replacement is continued in the very same way it was meant to, if the agency’s leader catastrophically fails in midst of its execution.
How could you use ArangoDB as a consensus service
The online documentation describes how such an ArangoDB RAFT service is deployed on an odd (and arguably low) number of interconnected hosts.
During initial startup of such an agency the instances find each other, exchange identities and establish a clear key-value and program store. Once the initialisation phase is complete within typically a couple of seconds, the RAFT algorithm is established and the HTTP API is accessible and the replicated log is recording; the documentation is found here. Restarts of individual nodes of the agency must not influence the runtime behaviour and on a good network should go unnoticed.
The key-value store comes with some additional features such as assignment of time to live for entries and entire branches and the possibility of registering callbacks for arbitrary subsections. It also features transactions and allows one to precondition these transactions with high granularity.
Any distributed service could now use arangodb agencies for initialisation and configuration management in the very same way as we do with ArangoDB clusters through integration the HTTP-API.
But in addition, agents run local Foxx threads, which can be used to deploy a resilient monitoring and maintenance thread with access to the RAFT process with its replicated log and the current local RAFT personality.
Some initial performance and compliance test
Making claims about fault tolerance in a distributed deployment, needs some evidence to back that up. Failure scenarios clearly range all the way from malfunctioning network switches and fabric to crashed hosts or faulty hard disks. While the local sources of error as failing host hardware, can be dealt with in unit tests, it turns out that tests of correct function of such a distributed service is anything but trivial.
The main claim and minimum requirement: At all times any response from any member of the RAFT is true. Such a response could be the value of a requested key but it could also be that a preconditioned write to a particular key succeeded or failed. The nice to have and secondary goal: Performance.
Just a brief word on scalability of consensus deployments here. Consensus does not scale. The core nature of consensus could be most readily compared to that of a bottleneck. The amount of operation that go through a consensus deployment will be affected mostly by the number of members and the network’s quality. Not a big surprise when you think about how consensus is reached over back and forth of packets.
Jepsen
Thankfully, Kyle Kingsbury who has been extensively blogging about the subject of distributed correctness, has published a framework for running tests to that effect of github.
Kyle’s framework is a clojure library, which distills the findings of a couple of fundamental papers, which Kyle discusses on his blog into one flexible package. Kyle’s blog has taken the distributed world in a storm because of the way the tests are done and evaluated.
The tests are run and results are recorded as local time series on virtual machines, which are subject to random network partitioning and stability issues. The analysis then tries to find a valid ordering of the test results such that linearisability3 can be established.
Results
We have tested the ArangoDB agency inside Jepsen to validate that the agency does behave linear as above described. We have also stress tested the agency with hundreds of millions of requests over longer periods to both check memory leakage and compaction related issues. The tests show that ArangoDB is ready to be used as a fault tolerant distributed configuration management platform for small to large network appliances.
What is to come
Lookout for more in depth upcoming technical blogs, which will demonstrate best case scenarios for deploying ArangoDB agencies for your own network appliances. Also for 2017 we are planning more comprehensive and large-scale testing of linearisability over the entire ArangoDB cluster.
Examples
We have put together a small collection of go programs, which demonstrate some of the above concepts in hopes that you might find them helpful to get started on the ArangoDB agency at https://github.com/neunhoef/AgencyUsage
tldr;
Consensus is a key asset in distributed appliances. Groups of ArangoDB instances may be well integrated into appliance farms for initialisation and configuration management. Our own exhaustive tests have proven excellent dependability and resilience in vast scenarios of network and hardware failure.
_____________________________
References
1 Pease M, Shostak R and Lamport L. Reaching Agreement in the Presence of Faults. Journal of the Association for Computing Machinery, 27(2). 1980. pp 228-234
2 Ongaro D and Ousterhout J. In search of an understandable consensus algorithm. 2014 USENIX Annual Technical Conference (USENIX ATC 14). 2014. pp. 305-319
3 Herlihy MP and Wing JM. Linearizability: A Correctness Condition for Concurrent Objects. ACM Transactions on Programming Languages and Systems, 12(3). 1990. Pp.463-492
4 Max Neunhöfer. Creating Fault Tolerant Services on Mesos. Recording of the talk, MesosCon Asia 2016













 As part of the global acceleration,
As part of the global acceleration, 
